
YOLO-World: Advancing Object Detection Technology
Anonymous • March 23, 2024
Explore YOLO-World's breakthrough in object detection with real-time, open-vocabulary capabilities for enhanced visual recognition.
Exploring YOLO-World: A Comprehensive Overview
Introduction to YOLO-World
YOLO-World is a groundbreaking real-time open-vocabulary object detection model based on the Ultralytics YOLOv8 framework. It addresses the limitations of traditional object detectors that rely on predefined object categories, restricting their utility in dynamic scenarios. YOLO-World introduces open-vocabulary detection capabilities by leveraging vision-language modeling and pre-training on extensive datasets.
The model excels at identifying a wide array of objects in zero-shot scenarios with unparalleled efficiency. By harnessing the computational speed of Convolutional Neural Networks (CNNs), YOLO-World delivers swift open-vocabulary detection results, catering to industries that require immediate outcomes. This innovative approach significantly lowers computational demands while maintaining competitive performance, making it a versatile tool for numerous vision-based applications.
Key Features and Advancements
YOLO-World boasts several key features that set it apart from existing open-vocabulary detectors:
-
Efficiency and Performance: YOLO-World substantially reduces computational and resource requirements without compromising performance. It offers a robust alternative to models like Segment Anything Model (SAM) but at a fraction of the computational cost, enabling real-time applications.
-
Inference with Offline Vocabulary: The model introduces a "prompt-then-detect" strategy, employing an offline vocabulary to further enhance efficiency. This approach allows the use of custom prompts computed apriori, including captions or categories, which are encoded and stored as offline vocabulary embeddings, streamlining the detection process.
-
Powered by YOLOv8: Built upon Ultralytics YOLOv8, YOLO-World leverages the latest advancements in real-time object detection to facilitate open-vocabulary detection with unparalleled accuracy and speed.
-
Benchmark Excellence: YOLO-World outperforms existing open-vocabulary detectors, including MDETR and GLIP series, in terms of speed and efficiency on standard benchmarks. It showcases YOLOv8's superior capability on a single NVIDIA V100 GPU.
-
Re-parameterizable Vision-Language Path Aggregation Network (RepVL-PAN): YOLO-World introduces RepVL-PAN, which facilitates the interaction between multi-scale image features and text embeddings. This innovative architecture enhances the model's ability to effectively process and integrate visual and linguistic information.
-
Region-Text Contrastive Loss: The model employs a region-text contrastive loss function to strengthen the alignment between visual regions and corresponding textual descriptions. This approach improves the model's ability to accurately associate objects with their textual representations.
2. YOLO-World in Action: Real-World Applications
YOLO-World's innovative approach to open-vocabulary object detection has significant implications for a wide range of real-world applications. By enabling efficient and adaptable detection without the need for extensive training or predefined categories, YOLO-World opens up new possibilities across diverse domains.
2.1 Object Detection Across Diverse Domains
One of the key strengths of YOLO-World is its versatility in handling object detection tasks across various industries and use cases. From surveillance and security to autonomous vehicles and robotics, YOLO-World's real-time performance and open-vocabulary capabilities make it a valuable tool for numerous applications.
In the realm of surveillance and security, YOLO-World can be employed to detect and track objects of interest, such as suspicious individuals or vehicles, in real-time. By leveraging user-generated prompts, the model can adapt to specific security scenarios and provide timely alerts.
Similarly, in the automotive industry, YOLO-World can enhance the perception capabilities of autonomous vehicles. By detecting and classifying objects on the road, such as pedestrians, traffic signs, and other vehicles, YOLO-World can contribute to safer and more efficient navigation.
2.2 Enhancing Performance with Zero-Shot Learning
YOLO-World's zero-shot learning capability is a game-changer for real-world applications. Traditional object detection models often require extensive training on large datasets with predefined categories. This process can be time-consuming and resource-intensive, limiting the flexibility and scalability of these models.
In contrast, YOLO-World's zero-shot learning allows for on-the-fly detection of objects based on user-generated prompts. This means that the model can adapt to new objects and scenarios without the need for additional training data or manual labeling.
For example, in industrial settings, YOLO-World can be used for quality control and defect detection. By providing prompts describing specific defects or anomalies, the model can quickly identify and localize these issues, streamlining the inspection process and reducing downtime.
Moreover, YOLO-World's zero-shot learning enables rapid prototyping and deployment of object detection solutions. Developers and researchers can quickly iterate and test different prompts to optimize the model's performance for specific use cases, without the overhead of extensive data collection and labeling.
Technical Deep Dive: YOLO-World Architecture and Performance
Understanding the Architecture
YOLO-World's architecture consists of three key elements:
- YOLO detector - based on Ultralytics YOLOv8; extracts the multi-scale features from the input image.
- Text Encoder - Transformer text encoder pre-trained by OpenAI's CLIP; encodes the text into text embeddings.
- Re-parameterizable Vision-Language Path Aggregation Network (RepVL-PAN) - performs multi-level cross-modality fusion between image features and text embeddings.
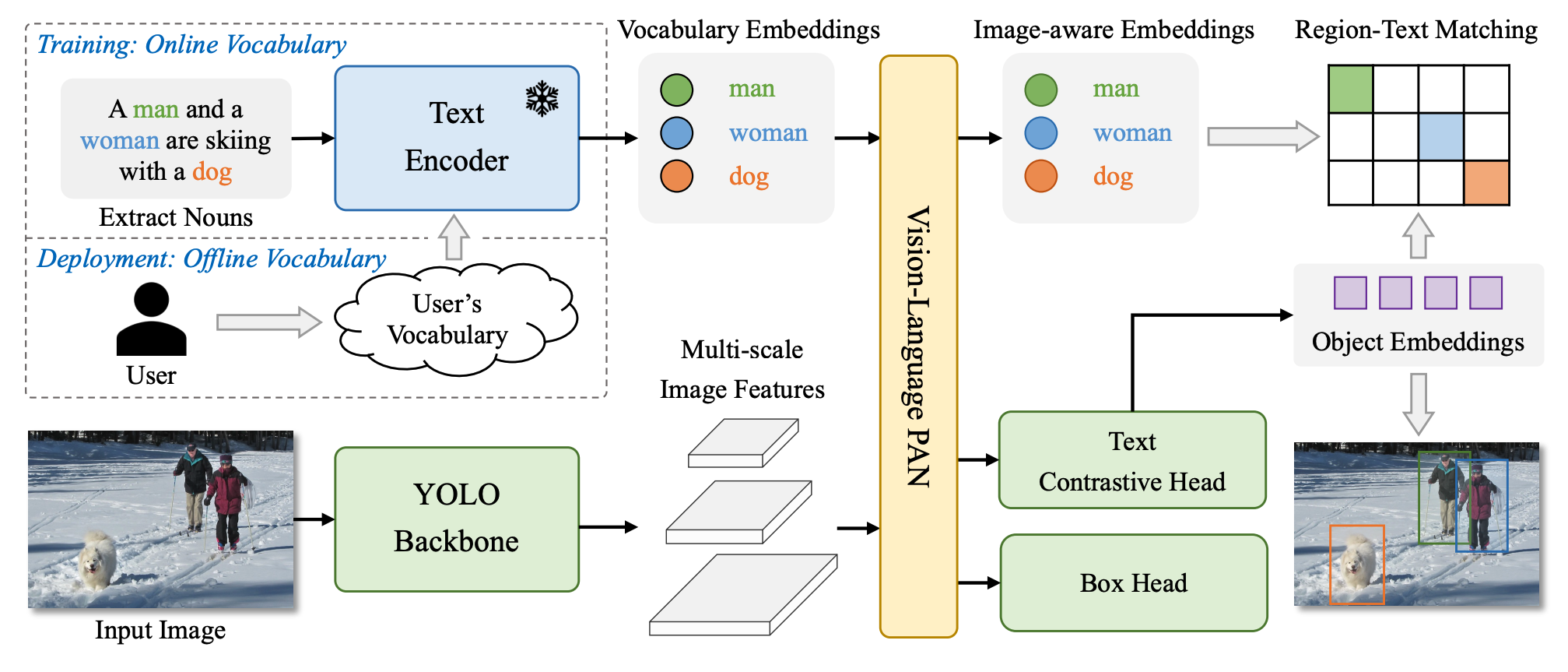 Figure 1. Overall Architecture of YOLO-World. Source: YOLO-World paper.
Figure 1. Overall Architecture of YOLO-World. Source: YOLO-World paper.
The fusion between image features and text embeddings is implemented via:
- Text-guided Cross Stage Partial Layer (T-CSPLayer): Built on top of the C2f layer, used in the YOLOv8 architecture, by adding text guidance into multi-scale image features. This is achieved through the Max Sigmoid Attention Block, which computes attention weights based on the interaction between text guidance and spatial features of the image. These weights are then applied to modulate the feature maps, enabling the network to focus more on areas relevant to the text descriptions.
- Image-Pooling Attention: Optimizes text embeddings with visual context by applying max pooling to multi-scale image features, thus distilling them into 27 patch tokens that encapsulate essential regional data. These tokens are then transformed through a process involving queries derived from text embeddings and keys and values from image patches, to compute scaled dot-product attention weights.
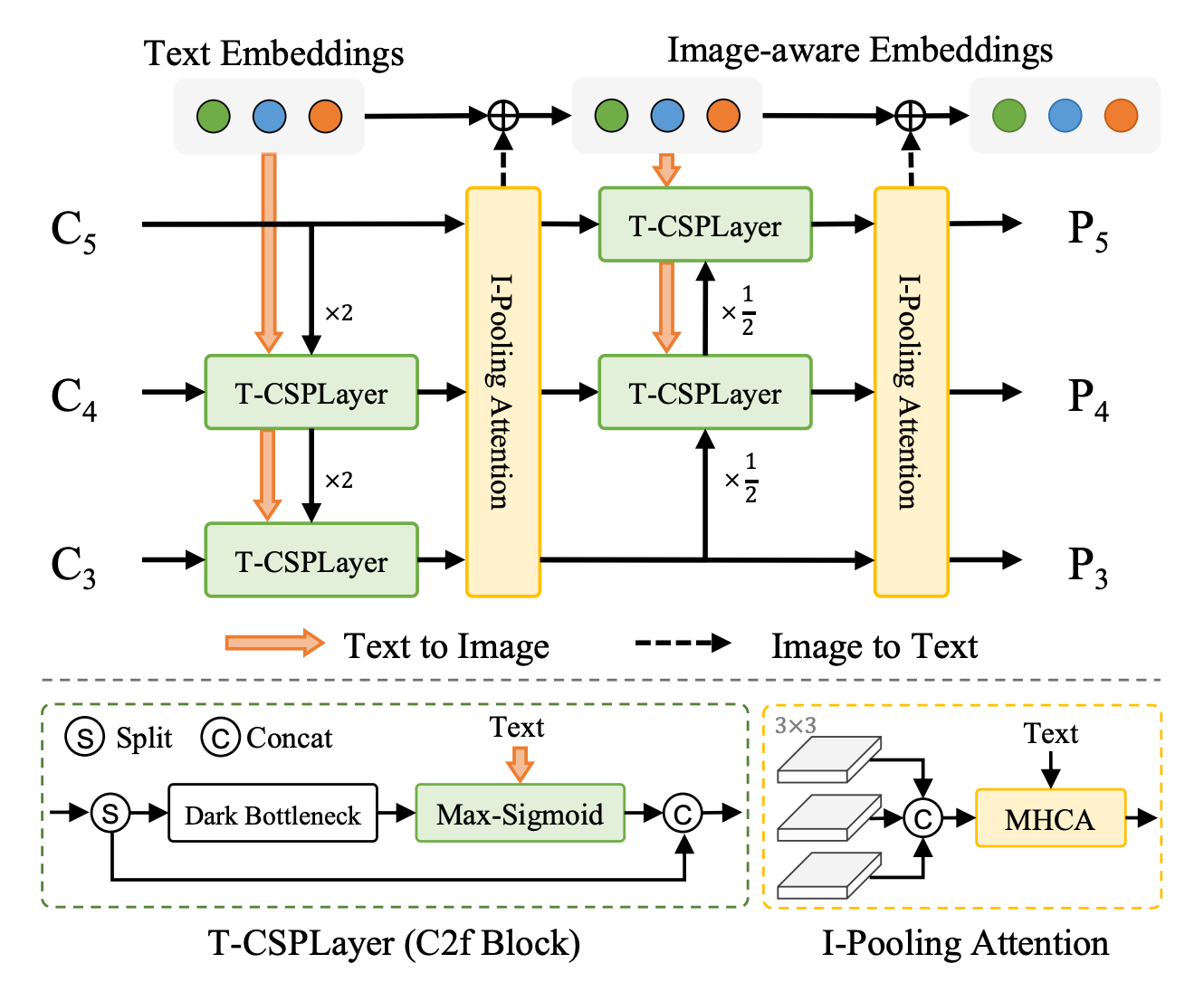 Figure 2. Text-guided Cross Stage Partial Layer [T-CSPLayer]. Source: YOLO-World paper.
Figure 2. Text-guided Cross Stage Partial Layer [T-CSPLayer]. Source: YOLO-World paper.
Evaluating Performance Metrics
YOLO-World follows on from a series of zero-shot object detection models released last year. These models, capable of identifying an object without fine-tuning, are typically slow and resource-intensive.
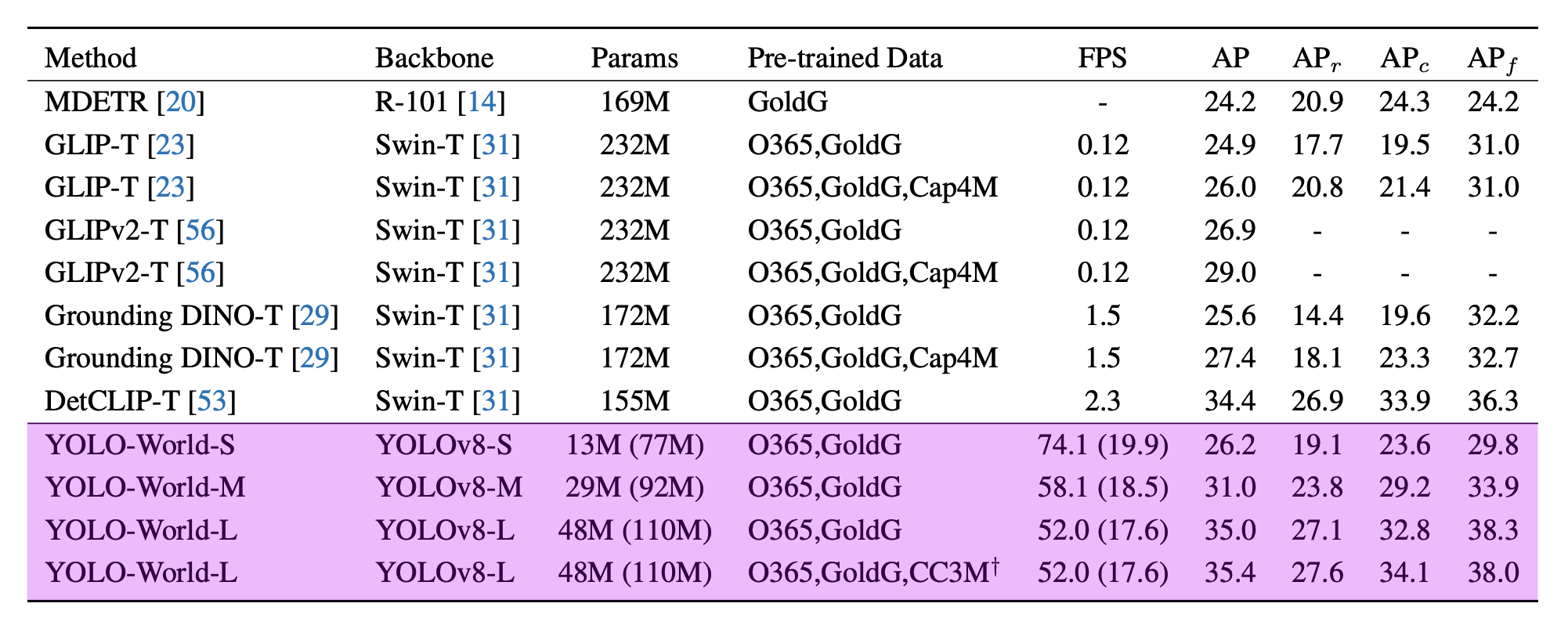 Table 1. Zero-shot Evaluation on LVIS. Source: YOLO-World paper.
Table 1. Zero-shot Evaluation on LVIS. Source: YOLO-World paper.
YOLO-World provides three models:
- Small with 13M (re-parametrized 77M) parameters
- Medium with 29M (re-parametrized 92M) parameters
- Large with 48M (re-parametrized 110M) parameters
The YOLO-World team benchmarked the model on the LVIS dataset and measured their performance on the V100 without any performance acceleration mechanisms like quantization or TensorRT.
According to the paper, YOLO-World reached between 35.4 AP with 52.0 FPS for the large version and 26.2 AP with 74.1 FPS for the small version. While the V100 is a powerful GPU, achieving such high FPS on any device is impressive.
The model's architecture, leveraging the efficient YOLO detector backbone combined with the RepVL-PAN for cross-modality fusion, enables it to achieve state-of-the-art performance in terms of both accuracy and speed for zero-shot object detection tasks. This makes YOLO-World a promising solution for real-world applications requiring dynamic and flexible object detection capabilities.
Subscribe to our newsletter
Get the latest updates